

Текстовая оптимизация включает в себя различные методы и стратегии, направленные на улучшение релевантности страницы для поисковых систем и пользователей. Она основана на учете текстовых факторов ранжирования, которые могут влиять на позицию страницы в результатах поиска.
В этой статье расскажем:
- Почему текстовый анализ сейчас эффективнее ссылочного продвижения.
- Что не так с вашим сниппетом и как нужно заполнять Title и Description.
- Как определять поисковый спрос на ключевые слова и анализировать конкурентов.
- Почему нет смысла проверять текст через тонну сервисов, оценивающих технические параметры семантики.
- Как сделать ТЗ для копирайтера, чтобы с первого раза получить нужный результат.
Те, кто готов работать над оптимизацией текста, получат свое место в топе поисковой выдачи Google и «Яндекс».
Поговорим для начала про нулевую позицию Zero Click
Нулевая позиция выдачи (Zero Click) — это ситуация, когда пользователь получает ответ на свой поисковый запрос непосредственно на странице поисковика, без необходимости переходить на другие веб-сайты. Вместо того, чтобы кликнуть на ссылку и перейти на страницу с результатами, пользователь может найти ответ на свой запрос в специальном блоке, известном как «featured snippet», «выбранный фрагмент» или «ответное окно», который отображается прямо на странице результатов поиска.
Нулевая позиция выдачи возникает благодаря алгоритмам поисковых систем, которые стремятся предоставить пользователю максимально релевантную информацию на самой странице поиска. Это может быть ответ на конкретный вопрос, определенные данные, определения, расписания, рецепты и т. д. Featured snippets представляют собой выделенные блоки с краткими ответами на запросы пользователей.
Нулевая позиция выдачи может быть полезна для пользователей, так как они могут получить ответ на свой вопрос быстро и без необходимости переходить на другие сайты. Однако это может означать потерю трафика для веб-сайтов, поскольку пользователи могут не кликать на ссылки и не посещать другие страницы. Для веб-мастеров и владельцев сайтов это означает, что важно оптимизировать свой контент и структуру сайта таким образом, чтобы иметь больше шансов появиться в нулевой позиции выдачи и привлечь пользователей к дополнительному изучению контента на своем сайте.
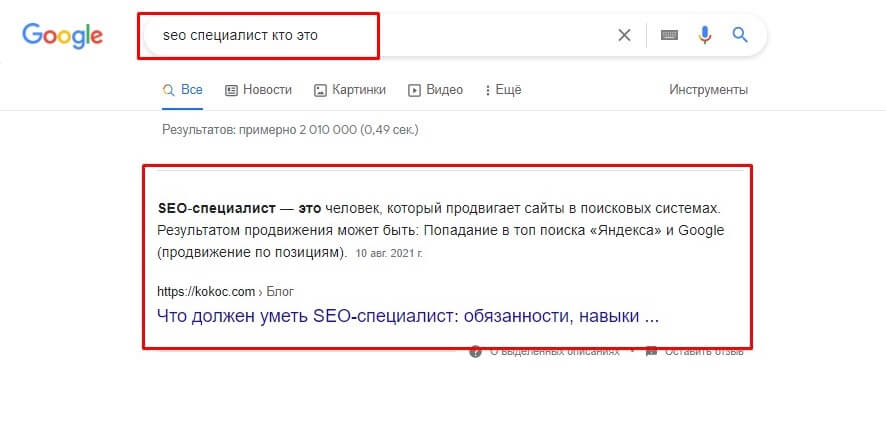 Пример страницы, которая находится на позиции Zero Clic
Пример страницы, которая находится на позиции Zero Clic
Мы поделимся, как выжать максимум из текста для SEO и перехватить у конкурентов большую часть трафика по поисковому запросу.
Текстовая оптимизация информационных текстов
Работа над текстовой оптимизацией начинается еще до написания самой статьи. SEO — это всегда про продажи. Смысл поискового продвижения заключается в привлечении трафика из органической выдачи поисковых систем, который в дальнейшем можно конвертировать в лиды и сделки.
Собираем семантику для статьи
Когда вы собираете семантику для статьи, вам нужно составить список ключевых слов и фраз, которые связаны с темой статьи и которые могут быть релевантны для вашей аудитории.Для этого определяются поисковые запросы, которые могут принести трафик, и собирается семантика для будущего текста.
Оцениваем поисковый спрос и собираем ключевые слова
Все страницы сайта продвигаются под семантическое ядро.
Оценка поискового спроса и сбор ключевых слов важны для понимания того, какие термины и фразы используются пользователи при поиске информации в связи с вашей темой. Вот несколько шагов, которые помогут вам в этом процессе:
- Используйте инструменты для исследования ключевых слов: Существуют различные инструменты, такие как Google Keyword Planner, SEMrush, Ahrefs и другие, которые позволяют исследовать объем поиска и конкуренцию для определенных ключевых слов и фраз. Используйте эти инструменты, чтобы получить представление о том, какие ключевые слова и фразы популярны среди пользователей.
- Анализируйте поисковые выдачи: Проведите поиск по ключевым словам и фразам, связанным с вашей темой, и проанализируйте результаты поиска. Обратите внимание на заголовки статей, вопросы, которые возникают в «выбранных фрагментах» (featured snippets), и другие элементы, которые указывают на актуальные ключевые слова и темы.
- Расширяйте список ключевых слов: Начните с основных ключевых слов, связанных с вашей темой, а затем расширьте список, включая синонимы, вариации слов, связанные понятия и более детальные фразы. Используйте инструменты для поиска синонимов или просто проводите поиск в поисковых системах, чтобы найти различные варианты ключевых слов.
- Учитывайте местные запросы: Если ваша статья ориентирована на конкретный регион или страну, учтите местные запросы и ключевые слова, которые могут быть важными для вашей целевой аудитории.
- Анализируйте конкуренцию: Оцените конкуренцию для выбранных ключевых слов и фраз. Учитывайте объем поиска и уровень конкуренции, чтобы определить, насколько реалистично ранжировать ваш контент по этим ключевым словам.
- Обновляйте и дополняйте список: Собранный список ключевых слов и фраз может быть основой для оптимизации вашей статьи. Однако будьте готовы к тому, что список может быть подвержен изменениям и дополнениям по мере развития вашей статьи и новых исследований.
- Распределите ключевые слова по приоритету: Отсортируйте ключевые слова и фразы по их значимости и релевантности для вашей статьи. Определите основные ключевые слова, которые должны быть включены в заголовок, подзаголовки и основной текст статьи. Распределите остальные ключевые слова по разделам или абзацам в зависимости от их контекстной связи.
- Используйте ключевые слова органично: Важно включать ключевые слова и фразы в свой контент естественным образом. Избегайте избыточной ключевой загруженности, поскольку это может негативно повлиять на читабельность и качество статьи. Старайтесь включать ключевые слова в заголовки, начало абзацев и важные места, но только если они органично вписываются в контекст.
- Учитывайте поисковую интент: Помимо ключевых слов, учтите также поисковую интент — намерение пользователей при проведении поиска. Подумайте о том, какую информацию и ответы ищут пользователи, связанные с вашей темой, и старайтесь предоставить полезный и соответствующий контент.
- Проверьте результаты: После оптимизации статьи отслеживайте ее позиции в поисковых результатах и анализируйте трафик, который она привлекает. Если нужно, внесите корректировки в ключевые слова и фразы, чтобы улучшить ранжирование и привлечь более целевую аудиторию.
Помните, что семантика и ключевые слова — это важный аспект оптимизации контента для поисковых систем, но также не забывайте о создании качественного и информативного контента, который будет полезен вашей аудитории.
Разберем это на наглядном примере. Допустим, стоит задача привлечь трафик по запросу “пинается коробка автомат”, чтобы рассказать потенциальному клиенту о проблемах с трансмиссиями, убедить его в своей экспертности и привлечь его на верхнюю ступень воронки продаж. Если сформированного спроса на услуги компании еще нет, проводим оценку.
Сначала заходим в «Яндекс.Вордстат». Указываем главный поисковый запрос, по которому планируется создать текст для SEO:
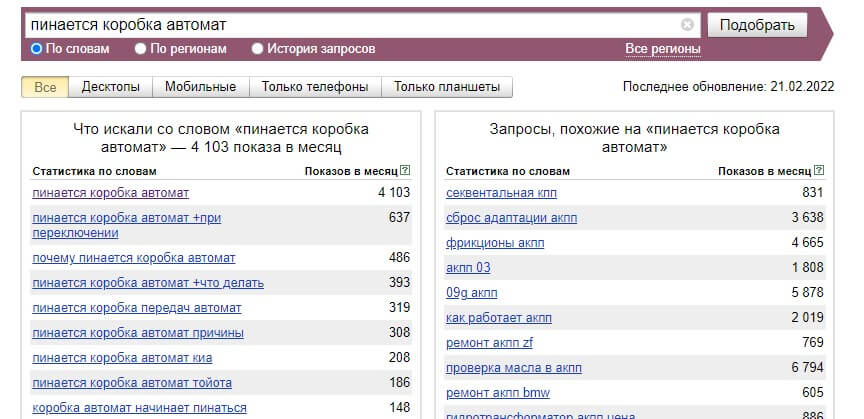 Пример выдачи «Яндекс.Вордстат» к поисковому запросу “пинается коробка автомат”
Пример выдачи «Яндекс.Вордстат» к поисковому запросу “пинается коробка автомат”
Для удобства работы с «Яндекс.Вордстат» можно скачать расширение для браузера Yandex Wordstat Assistant. Программа сохранит все собранные ключевые слова в буфере обмена, после чего семантику можно будет скопировать в таблицу в один клик. Без расширения каждый поисковый запрос придется копировать по отдельности.
При сборе ключевых слов задача — максимально расширить семантику для посадочной страницы целевыми запросами. Целевыми можно назвать все ключевые слова, которые относятся к теме продвигаемой страницы, имеют одинаковый интент — поисковое намерение пользователя.
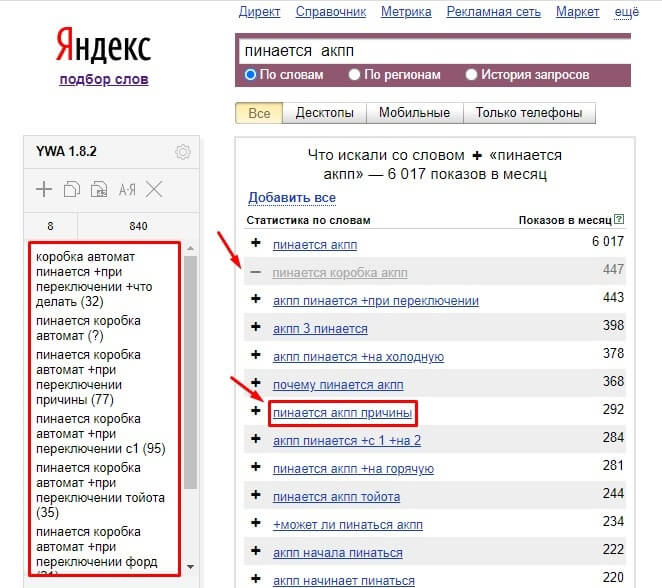
Нажимаем на «+» напротив целевого запроса, чтобы скопировать ключевое слово и его частотность через расширение
Частотность (или объем поиска) отражает количество поисковых запросов, которые пользователи совершают в поисковых системах по конкретному ключевому слову или фразе в определенный период времени. Чем выше цифра частотности, тем чаще пользователи ищут данное ключевое слово или фразу.
Инструменты, такие как «Вордстат» (WordStat) от Яндекса или Google Keyword Planner, предоставляют информацию о частотности поискового запроса на основе собранных данных о поисковых запросах пользователей. Эти инструменты помогают вам определить, насколько популярен или востребован определенный запрос.
Высокая частотность указывает на то, что запрос является популярным среди пользователей и может быть высоко конкурентным, поскольку множество веб-сайтов может стремиться ранжировать свои страницы по этому запросу. Но высокая частотность также может означать больший потенциал для привлечения большого количества трафика, если вы сможете оптимизировать свой контент для этого запроса.
Собранные ключевые слова вместе с частотностью копируем с помощью расширения Yandex Wordstat Assistant в таблицу Excel. В дальнейшем таблица будет использоваться для обработки семантики, разработку структуры текста при анализе конкурентов и как инструмент для удобного составления технического задания.
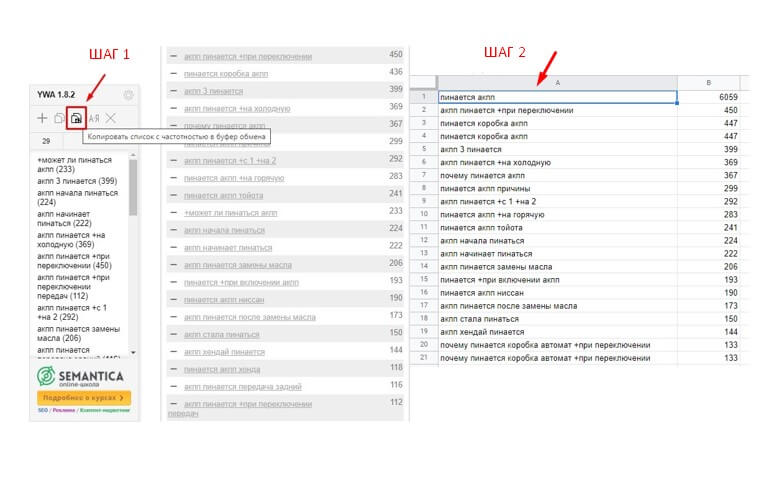 Копируем семантику с частотностью в таблицу для удобной работы в дальнейшем
Копируем семантику с частотностью в таблицу для удобной работы в дальнейшем
Для технической оптимизации одной страницы часто применяется ручная очистка семантики. Оптимизатор сам подбирает релевантные ключевые слова, которые лучше всего относятся тематике посадочной страницы. Менее очевидная семантика в дальнейшем будет отсеяна на этапе кластеризации и определения коммерческости.
Далее семантику в таблице нужно обогатить LSI, определить тип поисковых запросов и провести кластеризацию. Рассказываем зачем это нужно как и это сделать.
Работаем с LSI
LSI (Latent Semantic Indexing) — это метод анализа и индексирования текстовых документов, используемый поисковыми системами для понимания семантической связи между словами и понятиями. LSI помогает определить тематическую связь между словами, даже если они не являются синонимами или не встречаются вместе часто.
LSI основывается на предположении, что слова, которые часто появляются в одном контексте или вблизи друг от друга в документах, имеют схожую семантику или тематику. Алгоритм LSI использует математические методы, такие как сингулярное разложение (Singular Value Decomposition, SVD), для создания векторных представлений слов и документов, которые учитывают эту семантическую связь.
Поисковые системы, такие как Google, используют LSI для понимания контента веб-страниц и поисковых запросов пользователей. Это позволяет им показывать более релевантные результаты, даже если ключевые слова не совпадают точно. Например, если в вашем тексте упоминается «кошка», то LSI может понять, что вы также имеете в виду «кот», «животное» и другие связанные понятия.
Использование LSI в оптимизации контента позволяет создавать более естественный и разнообразный текст, который отражает семантическую связь между ключевыми словами и общую тематику. Вместо механического повторения ключевых слов можно включать синонимы, близкие понятия и связанные термины, чтобы создать более полный и информативный контент для поисковых систем и пользователей.
Быстро собрать LSI можно с помощью онлайн-сервисов, например, в Just-Magicинструментом «Акварель». Указываем в сервисе семантику и выбираем поисковую систему, где будут собираться LSI — далее запускаем задачу.
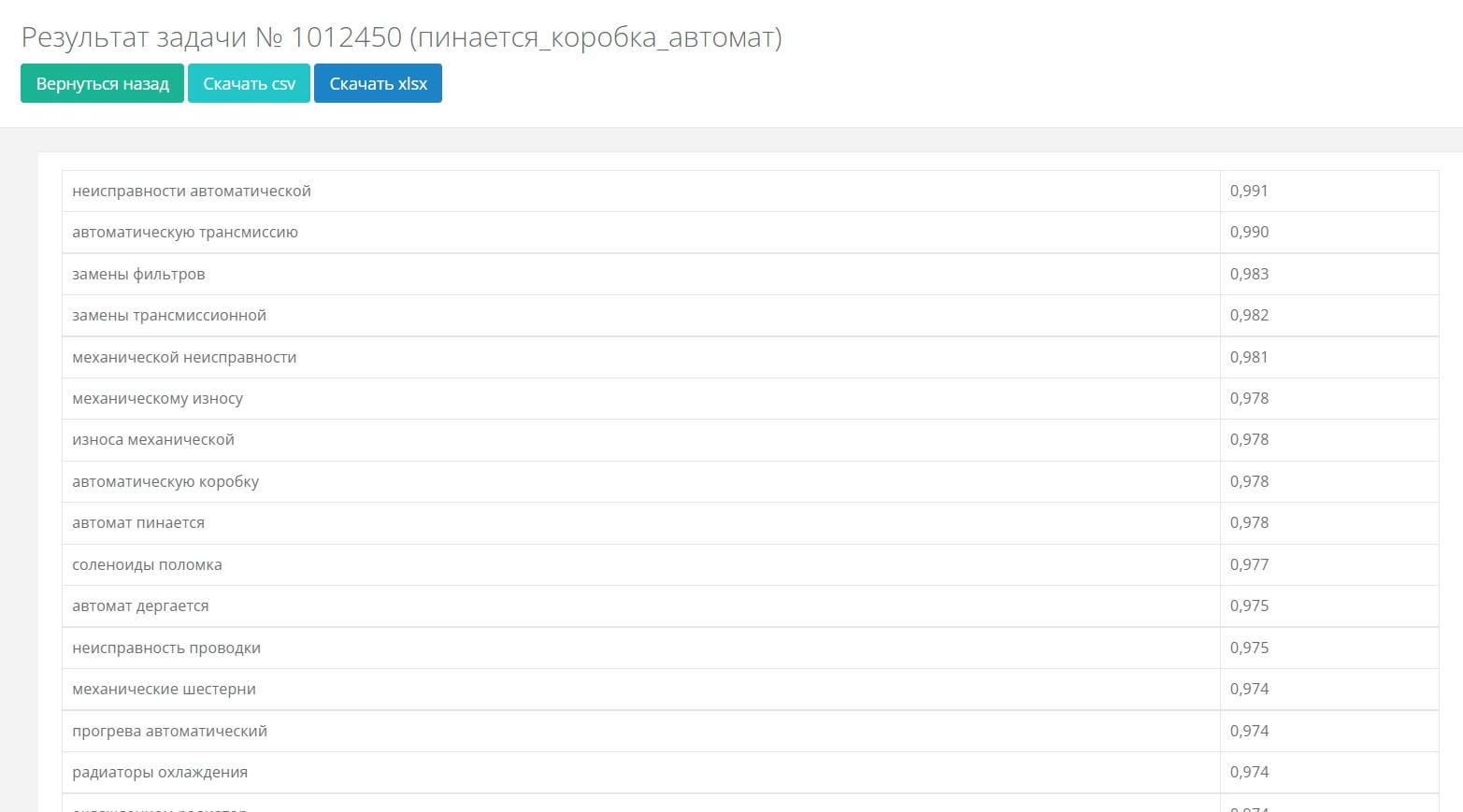 Сервис выдаст LSI, которые сделают текст более релевантным и менее спамным
Сервис выдаст LSI, которые сделают текст более релевантным и менее спамным
LSI поможет сделать текст более естественным и релевантным основному запросу: это улучшит индексацию поисковыми системами и поведенческие факторы.
Собранные слова LSI добавляются в будущее техническое задание для копирайтера рядом с поисковыми запросами и сформированной структурой текста. А пока добавляем собранные LSI в таблицу с нашей семантикой.
Кластеризация и определение интента
Кластеризация — это метод анализа данных, который используется для группировки схожих объектов внутри набора данных. Он основывается на схожести или близости между объектами в многомерном пространстве. В контексте текстового анализа, кластеризация может быть использована для группировки документов или текстовых фрагментов на основе их схожей семантики или тематики.
Например, при анализе большого объема текстовых данных, таких как статьи, новости или социальные медиа сообщения, можно применить алгоритм кластеризации, чтобы автоматически определить группы текстов с схожей тематикой или содержанием. Это может помочь в понимании структуры информации и выявлении скрытых тем или паттернов в данных.
Приведем пример разгруппировки ключевых слов с помощью сервиса Coolakov, который потом также поможет провести анализ конкурентов.
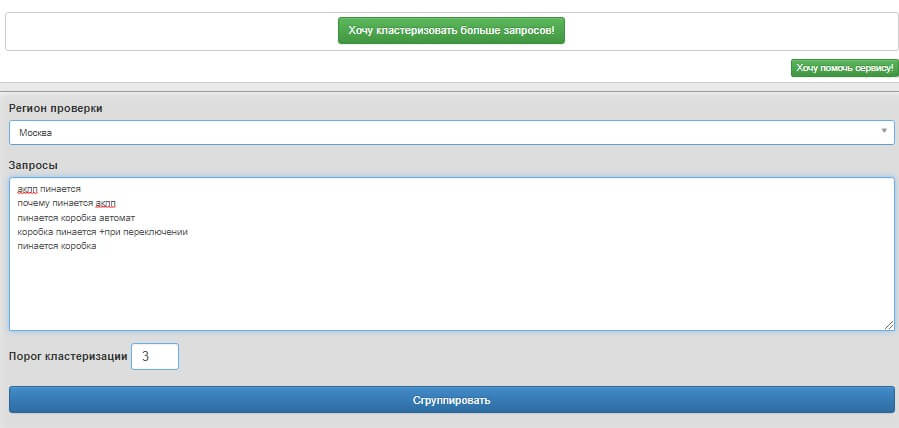 Указываем регион для проверки ключевых слов и всю собранную семантику для кластеризации
Указываем регион для проверки ключевых слов и всю собранную семантику для кластеризации
Сервис разгруппирует ключевые слова на кластеры — нам потребуется группа семантики, где находится основной поисковый запрос.
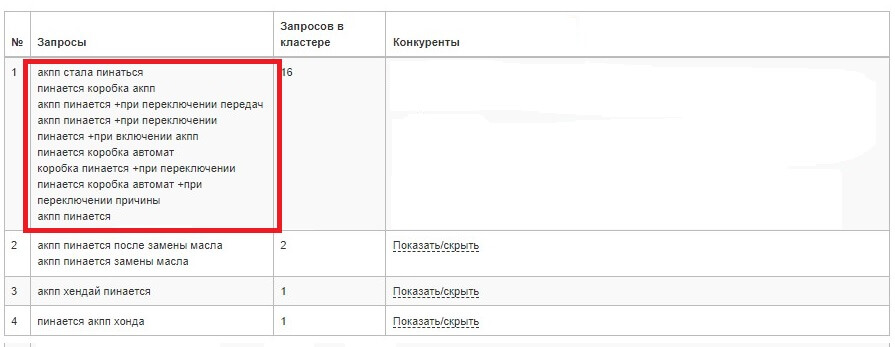 Результат кластеризации — осталось проверить коммерческость.
Результат кластеризации — осталось проверить коммерческость.
Неиспользованные кластеры можно использовать как базу для сбора новой семантики при создании и оптимизации других страниц сайта.
Теперь проверяем коммерческость запросов в кластере. Разберем это на примере сервиса Majento— загружаем ключевые слова и запускаем проверку.
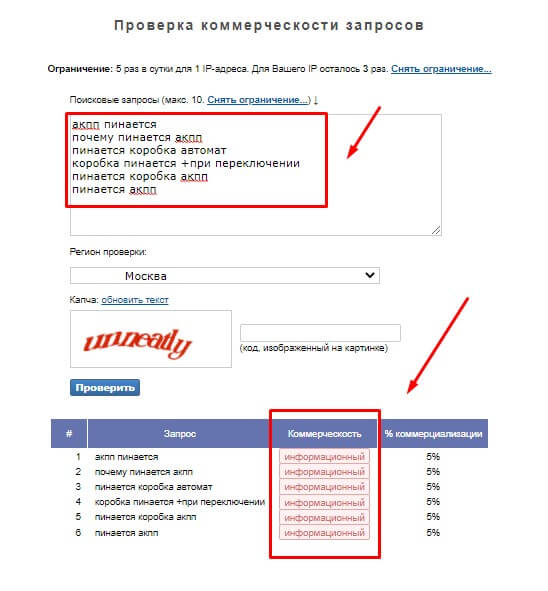
В нашем кластере все слова принадлежат одному интенту, удалять ничего не нужно
При оптимизации информационных страниц из кластера стоит удалить все слова с коммерческим интентом, и наоборот. Если процент коммерциализации находится в районе 45–65 % и интент смешанный, нужно смотреть на контекст страницы и сезонность поискового запроса. Смешивать ключевые слова с разным интентом на одной странице недопустимо — это размывает релевантность.
Теперь у нас есть список ключевых слов для статьи. Многие на этом останавливаются и сразу переходят к разработке технического задания для копирайтера, однако это только начало.
Анализируем конкурентов в выдаче
После сбора семантики важно определить, с кем нам придется конкурировать в поисковой выдаче. Анализ конкурентов сразу решает большой ряд вопросов, например:
- Какие поисковые запросы используются для лидогенерации.
- Какой объем текста должен быть у статьи.
- Какие формулировки хорошо работают в сниппетах и метатегах.
Необходимо определить страницы-лидеры, которые имеют наибольшую видимость по нашему ядру запросов.
Это можно сделать вручную, просканировав все сайты, либо с помощью бесплатного сервиса Coolakov. Выбираем инструмент «Определение конкурентов» и копируем выбранные поисковые запросы в сервис.
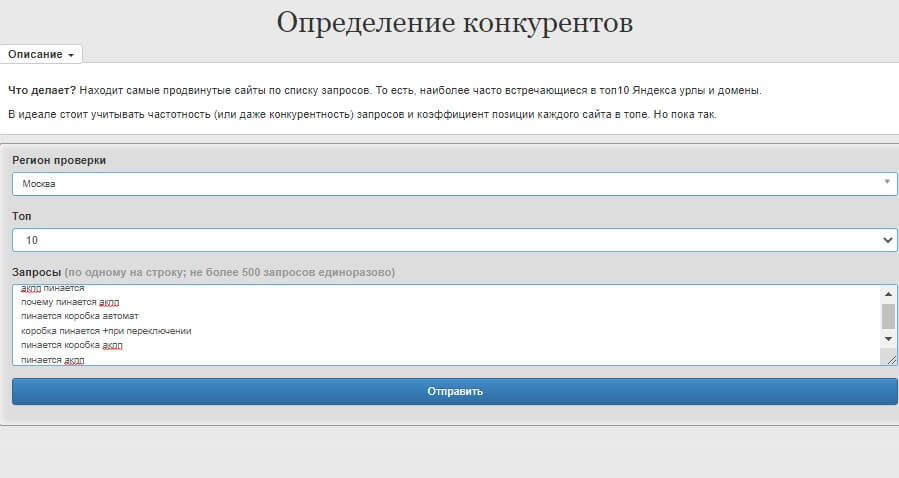 Выбираем размер выдачи и обязательно удаляем частотность рядом с ключевыми словами. Запускаем сканирование
Выбираем размер выдачи и обязательно удаляем частотность рядом с ключевыми словами. Запускаем сканирование
Это основные конкуренты, с которыми придется бороться за место в поисковой выдаче либо использовать в качестве референсов:
 Сервис выдал сайты, где пересекаются все запросы. Нас интересуют ресурсы с наибольшим показателем — в примере это 9–8 запросов
Сервис выдал сайты, где пересекаются все запросы. Нас интересуют ресурсы с наибольшим показателем — в примере это 9–8 запросов
Собранная семантика покрывает большую часть запросов, соответственно, эти сайты охватывают максимум поискового спроса.
Вероятность выхода в топ статьи, написанной с учетом структуры конкурентов, уже кратко выше, чем у текста, который написан просто при использовании ключевых слов из «Вордстата».
Вероятность выхода в топ статьи, написанной с учетом структуры конкурентов, уже кратко выше, чем у текста, который написан просто при использовании ключевых слов из «Вордстата».
Работаем над структурой текста
После анализа и оценки поискового спроса важно отойти от сканирования параметров конкурентов и уделить внимание смысловой релевантности будущего текста. Не нужно анализировать объем и тошнотность текста конкурентов: сейчас важнее грамотно проработать структуру статьи.
Для формирования костяка структуры парсятся заголовки H1–H6 конкурентов из топа.
Это можно сделать вручную или автоматизировать парсинг через бесплатный Click.ru. Инструменты сервиса помимо структуры из подзаголовков также спарсят метатеги. Для каждого аккаунта сервис предлагает 500 бесплатных запусков парсера, затем каждые 500 ссылок будут стоить 0,4 рубля.
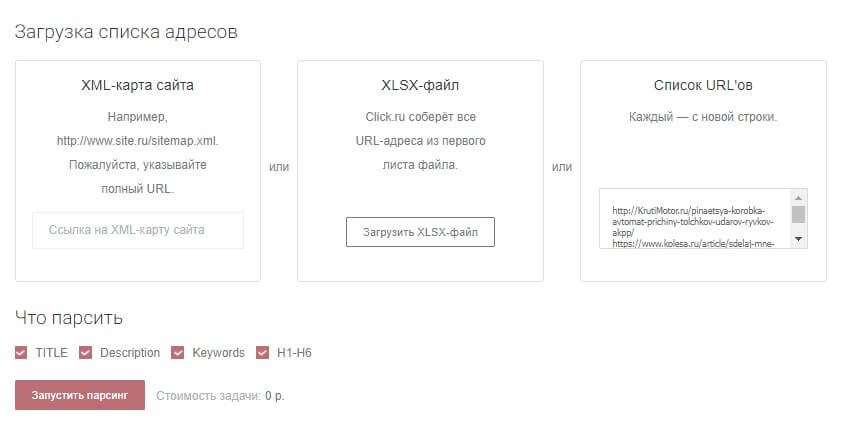 Копируем выбранных конкурентов из сервиса Coolakov и запускаем парсинг
Копируем выбранных конкурентов из сервиса Coolakov и запускаем парсинг
Сервис формирует таблицу, где будут все метатеги и заголовки H1–H6 сканируемых конкурентов. Если у конкурентов заполнен метатег Keywords, дополнительно сервис можно использовать для парсинга семантического ядра конкурентов.
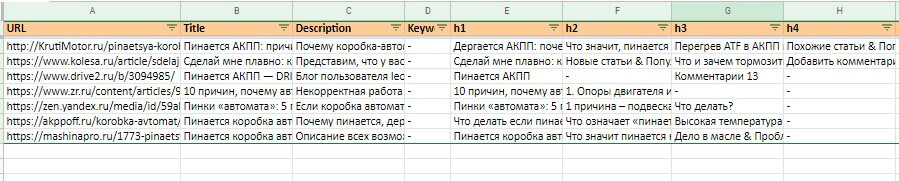 Результаты таблицы помогут сделать релевантную структуру текста согласно поисковому спросу
Результаты таблицы помогут сделать релевантную структуру текста согласно поисковому спросу
Таблица показывает, насколько хорошо проработана статья у конкурентов, покрывающих большую часть поискового спроса по выбранным ключевым словам. Задача SEO-специалиста или редактора на этом этапе — понять, как сделать еще лучше.
Собранные заголовки H1–H6 подскажут:
- Какие тезисы нужно собрать и раскрыть в статье.
- В какой последовательности нужно раскрывать тезисы.
- Что нужно добавить в текст, чтобы лучше раскрыть тему и сделать текст сильнее, чем у конкурентов.
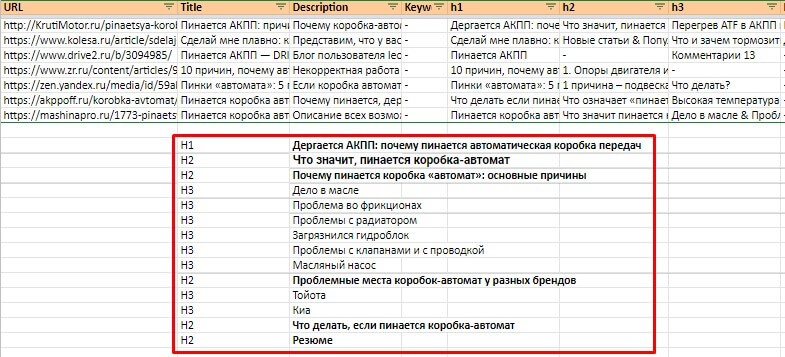
Вот примерная структура статьи, покрывающая поисковый спрос по запросам и не уступающая конкурентам из топ-10 выдачи
При разработке структуры стоит описать тезисный ответ на поисковый запрос в начале текста и затем приступать к освещению проблематики целевой аудитории и развернутому решению проблем. Сжатый, точечный ответ на главный поисковый запрос увеличит шансы на выход страницы в топ и улучшит поведенческие факторы.
Сниппет в поисковой выдаче заполняется аналогично коммерческим текстам для товаров. Основная цель — обеспечить высокий CTR. Для этого формируется Title, включающий поисковый запрос и УТП, а в Description добавляется тезисное раскрытие статьи.
При проработке структуры важно смотреть на смысловую содержательность и практическую ценность контента для целевой аудитории. В 2022 году стоит ориентироваться на параметры EAT — экспертность контента, а также уровень авторитета и доверия к источникам.
Для улучшения качества статьи и обхода конкурентов стоит:
- Добавить врезки экспертов в нише.
- Поделиться релевантным опытом, кейсами из практики.
- Контролировать актуальность и достоверность всех цифр и расчетов.
- Привести наглядные примеры — как в тексте, так и с помощью скриншотов.
Для информационных текстов большая часть работы на этом окончена. Теперь можно приступать к оптимизации коммерческих страниц и разработке технического задания.
Текстовая оптимизация коммерческих страниц
Оптимизация страниц, которые продвигаются по запросам с коммерческим намерением, отличается от SEO для информационных страниц. Вместо объемных текстовых описаний на страницах с коммерческим контентом более важным фактором является распределение семантики внутри ключевых зон документа. Первоначальные этапы оптимизации, такие как сбор семантики и кластеризация, остаются одинаковыми, но затем следует учет типа страницы — продвижение товаров или услуг.
После этого включается текстовый анализ, который позволяет определить, где и как нужно оптимизировать зоны документа, чтобы достичь топ-10 результатов в поисковой выдаче.
Зоны коммерческого документа
Рейтинг составлен по мере снижения значимости в документе (от большого к малому).
- Title (заголовок) в контексте оптимизации веб-страницы обозначает элемент HTML, который отображается в верхней части окна браузера и является одним из важных текстовых факторов ранжирования для поисковых систем. Заголовок страницы (title) является также заголовком, который отображается в результатах поиска. Оптимизированный заголовок страницы имеет большое значение для привлечения пользователей и поисковых систем. Он должен быть информативным, кратким и содержать ключевые слова, отражающие содержание страницы. Хорошо оптимизированный заголовок страницы может повысить релевантность страницы для поисковых запросов пользователей и увеличить ее видимость в поисковой выдаче.
- Анкор-лист —это список ключевых слов или фраз, которые используются в качестве текстовых ссылок, указывающих на другие страницы или ресурсы веб-сайта. Анкор-текст обычно выделяется синтаксически (чаще всего гиперссылкой) и кликабелен, позволяя пользователям переходить на связанные страницы. Анкор-лист является важным инструментом для оптимизации поисковых систем, поскольку он помогает установить связи между страницами веб-сайта, указывая на их релевантность и важность для конкретных ключевых слов или фраз. Это также позволяет поисковым системам лучше понять контекст и содержание связанных страниц.
- Текстовые фрагменты — небольшой текст в разных зонах документа: сюда входят HTML-заголовки, теги, подписи изображений, описание фильтров в каталоге и кнопки на странице. Это семантика, которая была использована при проработке UI-страницы сайта.
- Plain-текст — более объемный текст на странице, чем разрозненные тестовые фрагменты. Как правило, plain-текст состоит от 1 абзаца и включает больше 200–300 знаков содержимого. Plain-текст размещается для использования ключевых слов, которые не были органично использованы в более значимых зонах документа.
Чтобы управлять текстовой релевантностью, важно научиться распределять значимые для ранжирования слова в наиболее ценных зонах документа и не допускать переспама. Для точного расчета количества вхождений в каждую зону документа используется текстовый анализ.
Текстовый анализ коммерческих документов
Возвращаемся к Just Magic, с помощью которого собирали LSI. Теперь нужен инструмент « Текстовый анализ» — этапы работы с инструментом выглядят так:
- Формируем файл для загрузки, с его помощью можно проводить пакетный анализ, главное чтобы была правильно сделана кластеризация.
- Включаем “Соответствие по типу страниц” для того чтобы внутренние страницы не сравнивались с главными и наоборот.
- Добавляем в исключения сайты не соответствующие нашей “весовой категории” (avito.ru, drom.ru и т.д.).
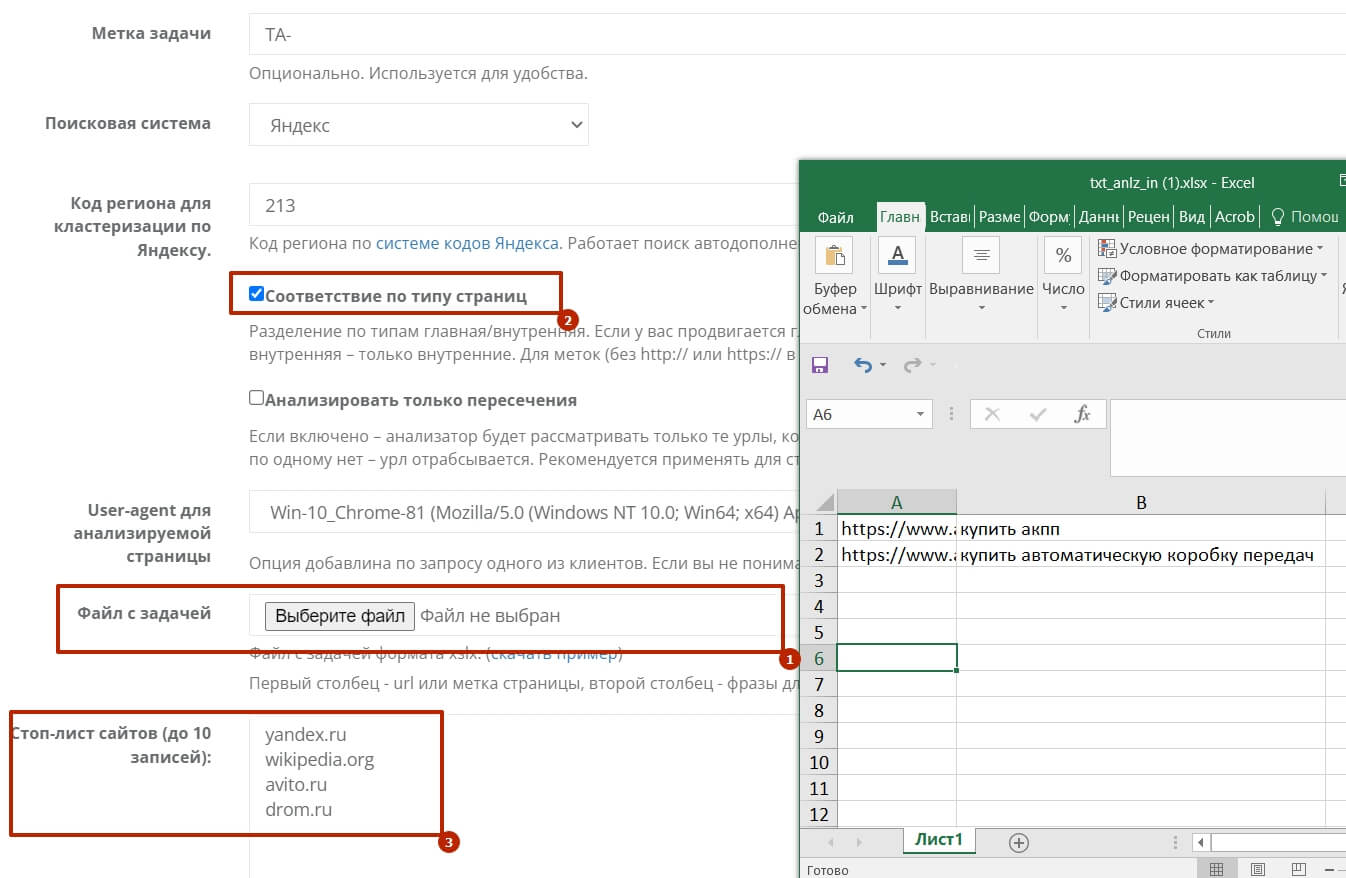 Вводим данные и запускаем задачу. Время текстового анализа занимает несколько минут.
Вводим данные и запускаем задачу. Время текстового анализа занимает несколько минут.
Инструмент просканирует конкурентов в топе выдачи и подскажет закономерность, которая поможет распределить семантику так, чтобы учесть все текстовые факторы ранжирования.
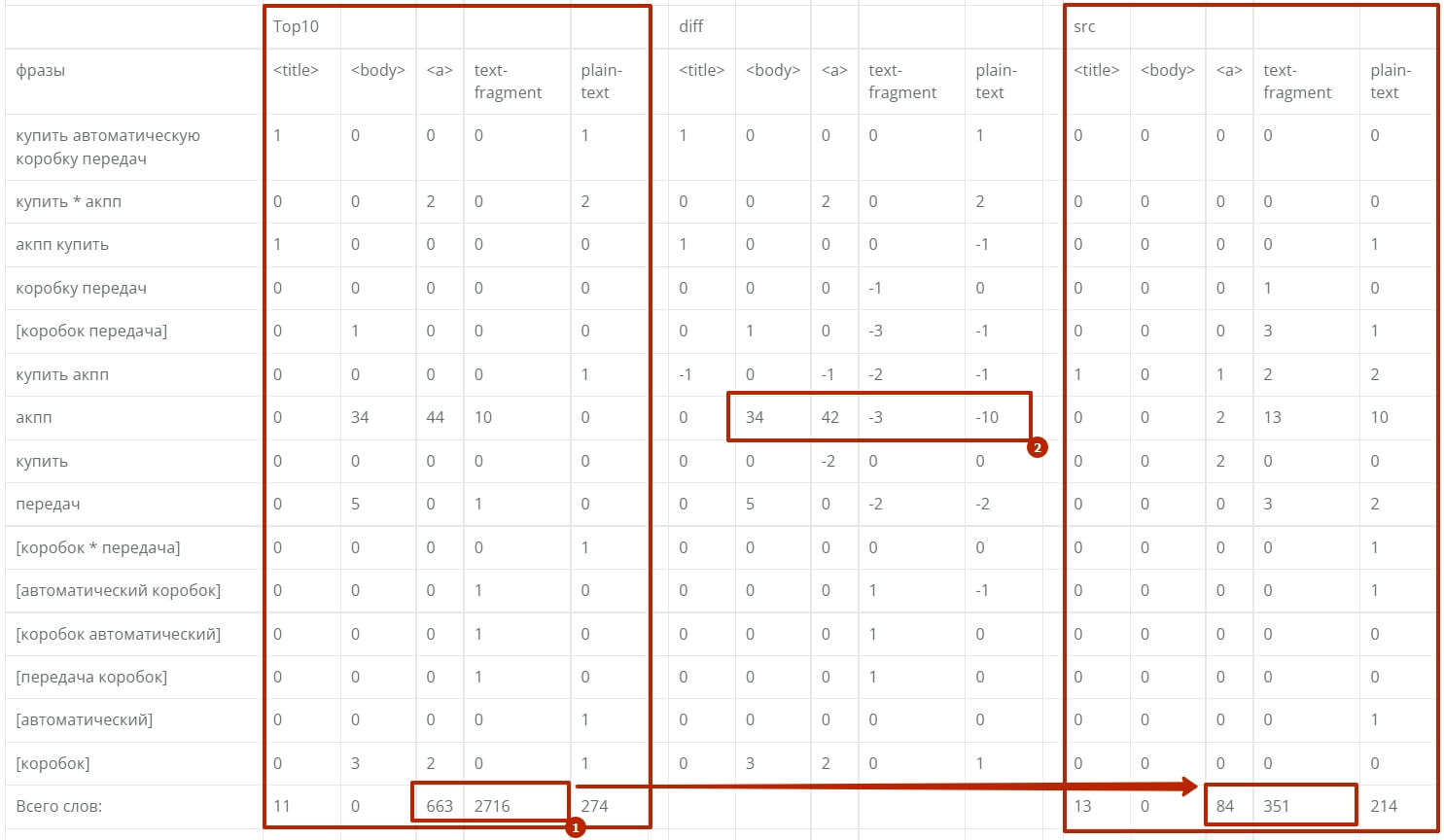 Результат текстового анализа по топу конкурентов.
Результат текстового анализа по топу конкурентов.
В полученном результате мы видим 3 столбца: Top10 — усредненные данные по ТОП-10, src — анализируемый сайт и diff — разница между ТОП-10 и нашим сайтом.
Анализируемый нами сайт находится в ТОП-30 и мы наблюдаем классические ошибки SEO-оптимизаторов, которые делают оптимизацию “на глазок”.
- Видим, что вместо вхождений в теги <a>, наш оптимизатор сделал привычный ему seo-текст (plain-text), который щедро дополнил ключевыми словами.
- Видим сильный перекос по количеству ключевых слов в зоне <a> такой объем характерен для большого товарного листинга, что наш оптимизатор не учел. И text-fragment — это могут быть текстовые описания у товаров, также в блоке листинга.
Разместив на странице товарный листинг на +- 42 позиции, а так же приведя текстовую составляющую к требуемому формату, сайт будет способен побороться за ТОП-10, а возможно и попадет туда сразу после переиндексации документа Яндексом.
Разница текстовой оптимизации товаров и услуг в e-commerce
Разберем отличия текстовой оптимизации коммерческих страниц с помощью тестового анализа при продвижении товаров и услуг по отдельности. Вес разных зон документа отличается для страниц товаров и услуг, что вносит свои коррективы в оптимизацию.
Оптимизация страниц с товарами. В интернет-магазинах часто классическое текстовое описание для оптимизации не требуется — влияние тестовых фрагментов и plain-зоны документа минимально. Для выхода в топ товарных страниц важна оптимизация блока листинга товаров. Здесь учитываются:
- Товарная матрица и полнота каталога интернет-магазина.
- Внутренняя перелинковка товаров в каталоге — анкор-лист.
- Название товаров — в карточках.
Текстовый анализ для оптимизации страниц услуг. Это страницы, которые создаются для продвижения сайта под запросы услуг компании, а не товаров — например, “ремонт акпп”.
На продвижение страниц с услугами влияют:
- Текстовые фрагменты — особенно HTML-заголовки.
- Plain-зона — большие тексты в несколько абзацев.
На вес слова при оценке релевантности также влияет расположение семантики в тексте. Чем ближе ключевые слова к началу документа, тем больше их вес и сильнее влияние на ранжирование.
После проработки текстовой оптимизации большое влияние для сайтов в e-commerce оказываются коммерческие факторы ранжирования.
Распределение веса слов — функция TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) — это статистическая мера, используемая в области информационного поиска и текстовой аналитики для оценки важности термина в контексте документа и коллекции документов.
TF (Term Frequency) отражает, насколько часто термин (слово) встречается в документе. Он рассчитывается путем подсчета числа раз, когда термин появляется в документе, и деления этого числа на общее количество слов в документе. TF показывает, насколько «важным» является термин в пределах конкретного документа.
IDF (Inverse Document Frequency) отражает редкость термина в коллекции документов. Он рассчитывается путем деления общего числа документов в коллекции на число документов, содержащих данный термин, и затем применения логарифмической функции к этому результату. IDF показывает, насколько «уникальным» является термин среди всех документов.
TF-IDF получается путем умножения значений TF и IDF. Он предоставляет числовую оценку, которая позволяет определить важность термина в конкретном документе относительно всей коллекции. Термины с высоким значением TF-IDF считаются более релевантными и информативными для данного документа.
TF-IDF широко используется в задачах текстового анализа, включая поиск информации, категоризацию документов, рекомендательные системы и анализ тональности текста. Он помогает выделить ключевые термины и определить их значимость для конкретного контекста или документа.

Вот как выглядит формула расчета TF-IDF
Как написать техническое задание для копирайтера
Теперь переходим к разработке технического задания — финального продукта, ради которого проводились парсинг, кластеризация и анализ.
Цель технического задания — объяснить копирайтеру, что нужно сделать для текста, чтобы получить статью, которая отражает смысловую, а не формальную релевантность поискового запроса.
Итак, мы разобрались:
- Как определяется релевантность текста.
- Как собирать семантику на основании поискового спроса.
- Что нужно учесть при составлении структуры статьи.
- Зачем проводить текстовый анализ.
Остается объединить все этапы работ и сформировать техническое задание. Разберем все по порядку и сформируем инструкцию:
- Оцените поисковый спрос. Подгоните выбранный поисковый запрос через «Яндекс.Вордстат» — определите частотность и сезонность главного ключевого слова.
- Обработайте семантику для статьи. Выберите все ключевые слова по теме или скопируйте готовый кластер семантического ядра. Определите поисковый интент кластера и соберите LSI.
- Определите конкурентов. Проанализируйте конкурентов с наибольшим покрытием собранных запросов в выдаче. Выявите полноту раскрытия темы, экспертность и формат изложения материала, пробелы в содержании. Пометьте, какие ключевые слова встречаются в текстах и комментариях на страницах конкурентов — расширьте семантику.
- Проведите текстовый анализ. Просканируйте тексты конкурентов и определите в каком направлении нужно вести оптимизацию — в сторону текстового наполнения или проработки структуры. Это разные пути текстовой оптимизации, каждый из которых применяется для конкретных задач — продвижения информационных страниц, товаров или услуг.
- Составьте структуру статьи. Определите, что нужно добавить в текст, чтобы полностью раскрыть тему и улучшить статью — составьте структуру и основные тезисы статьи. Расставьте приоритетные ключевые слова и LSI в наиболее важных зонах документа по TF-IDF, включая метатеги.
Оптимизация текста играет важную роль в достижении высоких позиций в результатах поиска в 2022 году. Современные методы оптимизации, такие как кластеризация, работа над структурой, расширение запросного индекса и текстовый анализ, позволяют эффективно использовать более 60% семантики вашего сайта для достижения топ-10 результатов в поисковых системах, таких как «Яндекс» и Google. Это в два раза более эффективно по сравнению с традиционными методами SEO. Чтобы быть в тренде и достичь успеха, важно максимально использовать современные практики в области оптимизации текста на вашем сайте.
 5573 0010
5573 0010

